物聯網時序數據庫Apache IoTDB是一款專為工業物聯網場景設計的高性能數據庫,其存儲引擎的高效性是其核心優勢之一。本文將深入解析IoTDB存儲引擎在數據處理與存儲支持服務方面的核心原理。
一、 數據模型與分層存儲結構
IoTDB采用“設備-時間序列”的數據模型,天然契合物聯網設備按時間產生數據的特性。其存儲引擎在邏輯上采用了分層、分區的設計:
- 存儲組:是數據分區的基本單位,一個存儲組對應一個獨立的存儲目錄和寫入鎖,實現了數據的物理隔離與并行寫入。用戶可根據業務需求(如按設備、按項目)靈活劃分存儲組,優化I/O。
- 時間分區:在每個存儲組內部,數據進一步按照時間范圍(可配置)進行分區。這種設計極大地提升了按時間范圍查詢的效率,并便于實施老舊數據的冷熱分層與生命周期管理。
二、 高效的數據處理流程
寫入與查詢是數據處理的兩大核心,IoTDB存儲引擎對此進行了深度優化。
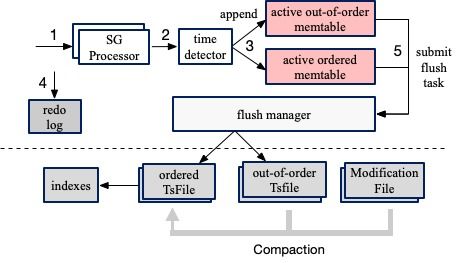
- 寫入流程:數據首先進入寫前日志(WAL),確保持久性。數據被寫入內存中的寫緩沖區(MemTable)。當MemTable寫滿或到達特定時間,會觸發刷寫操作,將其中的數據順序、壓縮地持久化到磁盤,形成一個不可變的順序數據文件(TsFile)。這種LSM-Tree(日志結構合并樹)的變體設計,將隨機寫轉換為順序寫,顯著提升了海量時間序列數據的高吞吐寫入性能。
- 查詢流程:查詢請求會根據時間范圍和存儲組/分區信息,快速定位到相關的TsFile。TsFile內部數據按時間順序存儲,并包含豐富的索引(如時間索引、設備級索引)。引擎能夠高效地進行時間過濾和值過濾,并利用預聚合的統計信息(如最大值、最小值)在文件級別進行快速剪枝,避免掃描無關數據,從而降低I/O開銷,實現低延遲查詢。
三、 核心存儲支持服務
為保障數據可靠性、可用性與可管理性,存儲引擎提供了一系列關鍵服務。
- 壓縮與編碼:這是存儲引擎節省空間的核心手段。IoTDB支持多種針對時間序列數據的專用編碼方式(如游程編碼RLE、二階差分編碼TS_2DIFF、Gorilla編碼等),在數據類型和模式已知的前提下,實現極高的壓縮比。文件級別也支持壓縮算法(如GZIP、LZ4),進一步降低存儲成本。
- 索引機制:除了TsFile內部索引,IoTDB還支持可選的倒排索引。它建立測量值(傳感器名)到包含該序列的TsFile的映射,使得在不指定設備路徑、僅根據傳感器名進行查詢時,也能快速定位數據文件,增強了查詢的靈活性。
- 數據生命周期管理與分層存儲:引擎支持基于時間的數據過期策略(TTL),自動清理過期數據。結合時間分區,可以輕松實現冷熱數據分離,將熱數據存儲在高速介質(如SSD),冷數據自動歸檔至低成本存儲(如對象存儲或HDFS),實現成本與性能的平衡。
- 數據一致性與恢復:寫前日志(WAL)是保證數據持久性和崩潰恢復的關鍵。在系統異常重啟后,可以通過重放WAL來恢復MemTable中未持久化的數據,確保數據不丟失。TsFile一旦生成即為不可變文件,這簡化了并發控制與數據一致性管理。
四、 TsFile:存儲的基石
TsFile是IoTDB自設計的列式存儲文件格式,是上述所有特性的載體。
- 列式存儲:同一時間序列的數據連續存儲,便于高效壓縮和針對單指標的快速掃描。
- 塊與頁結構:數據在文件中被組織為多個數據塊(Chunk),每個塊又包含多個頁(Page)。頁是壓縮和I/O的基本單位,這種結構有利于平衡壓縮效率與隨機讀取粒度。
- 豐富的元數據:文件頭尾包含詳細的元數據索引,如時間序列信息、統計信息、索引位置等,使得系統無需讀取整個文件即可快速定位所需數據塊。
Apache IoTDB的存儲引擎通過其貼合物聯網數據特性的分層模型、基于LSM-Tree的高效寫優化、列式存儲與專用編碼帶來的高壓縮比、以及精細的索引與分區策略,共同構建了一個能夠應對海量時序數據高吞吐寫入、低成本存儲與低延遲查詢挑戰的堅實基石。其內置的數據管理服務進一步確保了生產系統的可靠性、可維護性與經濟性。